IA moderna - a partir de 2017
Base Inicial - 2012-2017
Até os anos 2000, vários algoritmos de Machine Learning (ML) estavam bem estabelecidos e eram baseados em estatísticas e modelos matemáticos como Cadeias de Markov (topologia de redes neurais recorrentes (RNN), útil para análise de voz e entendimento de textos).
De 2012 a 2017, vários algoritmos de processamento de texto e imagem foram testados em grandes volumes de dados. Isto porque a partir de 2012 a NVidia disponibilizou placas computacionais baseadas em GPUs. Ou seja, placas de Unidades Gráficas que processavam informações em alto volume, pois podiam paralelizar cálculos com centenas, e hoje, milhares, de GPUs.
NVidia: https://www.nvidia.com/en-us/
De 2000 a 2016 vários algoritmos baseados em Deep-Learning (ANN profundas, Redes Neurais Profundas, com muitas hidden layers) foram propostos e ainda são utilizados até hoje. Em linguagem natural (ou NLP - natural language processing) as Redes Neurais Recorrentes foram implementadas, mas foram encontradas várias limitações (esta discussão esta fora do escopo deste texto: procure por Vanishing gradient problem). Porém, os algoritmos de imagens e vídeos tiveram um enorme sucesso e várias topologias como Redes Convolucionais (CNN - Convolutional Neural Network) foram implementadas e testadas. Apesar de superarem em muito a acurácia das ML tradicionais, também se encontrou limitações nas novas Depp Learnings.
A revolução das máquinas que conversam, ou seja, das máquinas que passam no teste de Turing começou em 2013, com dois artigos de pesquisadores da Google criando o conceito de embedding. Embedding é uma técnica de transformação de dados complexos em representações de menor dimensão, mais fáceis de processar. Esses modelos são o passo inicial para a utilização dos novos modelos de deep-learning, citados mais adiante.
Embedding é transformar textos em tokens (radical das palavras) e estes são transformados em vetores no espaço multidimensional de embeddings. Ou seja, dados 2000 livros, pode-se vetorizar cada frase, e tokens (ou conceitos) que são próximos no espaço dos textos, também deverão estar próximos no espaço de embedding. Portanto, poderemos encontrar um conjunto de palavras que definem um conceito semântico umas próximas às outras. Por exemplo: rei e rainha devem ficar perto um do outro e distantes de laranja e maçã. O mais interessante é que se pode fazer cálculos matemáticos de distâncias onde rei - rainha dever ter um distância próxima a homem - mulher, onde - é subtração e rei, rainha … e todas as palavras são vetores neste espaço.
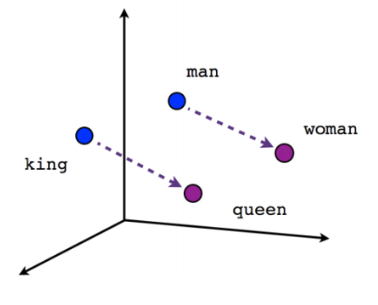
Uma transformada leva cada palavra (token) para o espaço matemático de embeddings - assume-se que após a análise de um texto, objetos semanticamente próximos nos textos estão também próximos no hiper-espaço matemático de embeddings (photo credit: Jaron Collis on Quora).
Miilov, Sutskever, Chen, Corrado e Dean, da Google, tiveram a brilhante ideia de construir o espaço/transformada de embeddings ao indagarem se a palavra (token) Air e Canada deveriam estar longe de Air Canada. O problema agora era criar este hiperespaço de embeddings e como treinar milhares de textos contendo milhões de palavras. As referências a seguir e vários artigos técnicos explicam como eles conseguiram, e hoje há algoritmos com Word2Vec que calculam esta transformação. Portanto, no espaço de embeddings (transformada de palavaras e conceitos) Air, Canada e Air Canada devem ser conceitos distintos e possivelmente distantes, já água deve estar próxima de air, USA e de Canada e airplane, airport e Delta Airlines próximo de Air Canada.
Referência: Mikolov T et al at Google; Distributed Representations of Words and Phrases and their Compositionality; 2013, Oct, https://doi.org/10.48550/arXiv.1310.454 Mikolov T et al at Google; Efficient Estimation of Word Representations in Vector Space; arXiv:1301.3781v3 [cs.CL] 7 Sep 2013
Deep-Learning a partir de 2017
Dois algoritmos transformaram a velha Deep Learning para a nova Deep Learning. Na velha deep learning os modelos todos eram baseados em ANNs na forma de MLP (multi-layer perceptons), mas a partir de 2017 topologias especializadas foram criadas.
Attention e Transformers
O primeiro artigo “Attention Is All You Need” foi publicado em 2017 por Vaswani, Shazeer, Parmar et al., da Google, onde os autores propuseram os Transformers. Um Transformer, é uma arquitetura de rede neural que dispensa a recorrência (RNN), ou seja, não utiliza RNN. Este modelo de ANN consegue mimetizar um mecanismo de autoatenção para traçar dependências globais entre entrada e saída de uma rede neural. Esse mecanismo consegue processar sentenças inteiras de uma só vez - em vez de uma sentença de cada vez - logo, a velocidade de treinamento e o custo de inferências diminuiram em comparação com as RNNs, especialmente por esta operação ser paralelizável. A arquitetura de Transformers revolucionou a NLP (processamento de linguagem natural), e este modelo também está sendo usado em procesamento de Imagens, Áudios, etc.
Referência: Vaswani et al, Google Brain, Attention Is All You Need, arXiv:1706.03762v5 [cs.CL] 6 Dec 2017
Nota
Onde estudar
para quem quiser ir mais a fundo há um execelente material em https://learn.deeplearning.ai/
há excelentes cursos no Coursera e Udemy
Aviso
Machine Learning envolve todos os estudos de algoritmos computacionais desenhados para raciocinar, classificar, clusterizar (aglomerar), ou fazer regressões. Deep Learning é uma subárea de ML que utilia ANN com muitas camadas neurais, fato que só foi possível a partir de 2012, aproximamente, com o advento das placas de processamento com centenas/milhares de GPUs. Ou seja, DL faz as mesmas tarefas que ML-clássica, porém, por conter muitos neurônios (percéptons) distribuídos em hidden layers, chega a uma precisão, sensiblidade e especificidade muito melhor.
BERT: Bidirectional Encoder Representations from Transformers
Assim como McCulloch e Pitts criaram o Neurônio Artificial pensando no Neurônio de Cajal, em 2018 pesquisadores da Google pensaram como mimetizar a Short Term Memory e a Long Term Memory, tão estudadas na neurologia. Ou seja, para se adivinhar uma palavra ou interpretar um texto, não basta conhecer o passado: frases e parágrafos anteriores! Ao se conhecer o futuro, frases e parágrafos posteriores, provavelmente a interpretação será muito mais acurada.
O BERT, Bidirectional Encoder Representations from Transformers, treina modelos de linguagem natural com base no conjunto completo de palavras de um texto. Esta técnica é denominada de treinamento bidirecional, uma vez que analisa palavras anteriores (passado) e palavras posteriores (futuro) em relação à palavra estudada num dado momento. Os modelos de NLP tradicionais são sempre treinados em ordem sequencial (indo para o futuro, para a direita do texto, só conhecendo o passado). Já o BERT foi denominado pela Google como um processo profundamente bidirecional, pela simples razão de que o verdadeiro significado das palavras só pode ser obtido conhecendo-se o passado e o futuro do texto ou palavra atual.
Por exemplo, seria difícil para uma máquina entender a palavra Canada, como sendo um país, mas conhecendo uma só palavra anterior Air Canada descobre que se trata de uma empresa aérea. Já meninas podem não ser crianças do sexo feminino, pois o texto a seguir relata “as meninas chegaram, disse D.Esthela, ao se referir às jovens senhoras com mais de 80 anos que vieram comemorar seu aniversário”.
Referência: Deep Learning Book (em português):
Estamos prontos para a nova era da IA
Agora, em 2018-2019, estamos prontos! Podemos treinar pequenos ou grandes modelos utilizandos os algoritmos de Attention e BERT para criar LLMs. Mas, o que são LLMs?